��ʲô�҂�Ҫ���衰AI�����{�ԡ���
�����g���p������“�ЈD������”���e�ԣ���Ϣ���挍���ɴ�׃�Ó�˷���x�� �^ȥ���꣬AI���ɵ��{�ԣ������ֵ�ҕ�l����������������ȫ���Խ������I�����a��ģʽ���E���γ�“�{��→AI����→�����{��”�Ă���朗l�� ������_��˹���罛��Փ���l���ġ�2025��ȫ���L�U��桷����“�e�`��̓����Ϣ”�c���b�_ͻ���O����⡢��������������O���О�2025��ȫ�����R������L�U�� ̓����Ϣ���H�`�����M�ߣ�߀���܌���������Ұ�ȫ��������Ⱥ��������ؔ�a��ȫ�������{�����У�AI���ڳɞ�����ͷŴ��e�`��̓����Ϣ����Ҫһ�h……
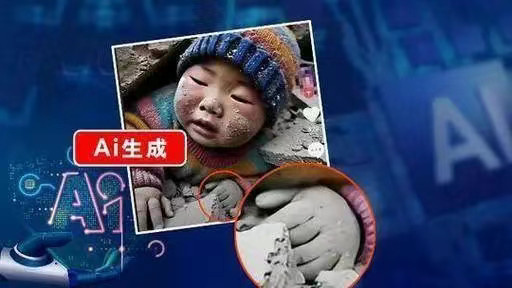
�½��ݳǿh�l������r�ڣ����{������AI���g�ֶΰl��̓����Ϣ�`�������� һЩ�W��ͨ�^AI�{�ն�������ƴ�����ӣ����Ť���������¹�Ԓ�}�����{�ԣ��Ɖ��������AI���g�ı��������������������á� ��һ߅��AI���X�cһЩ�˵�ä�Ž������ӄ����{�Ե��Ɖ�������ģ�ͻ��ڸ��ʵ�“����߉”��������Ⱦ���gȱ�����ɿ��ƺ��팍�t̓���ă��ݡ� �S������ʽAI���g���lʽ�lչ���W�j�{���c̓����Ϣ�ʬF���ܻ���Ҏģ�������l�������������Ĝ����c���g���j�g��ì��������J�� ����ƽ�AI���X���g�y�}����Դ�^����{�ԣ������˹����ܳɞ����{�̓���������S�������wϵ�����ɞ鮔�¾W�jݛՓ��������������}�� “����” AI�{�������������a ���������AI������������α�ע���{�����a���� ��̓����ĵ�����“�ƌW����”����ƴ���f�D������“�������x”��AI���ߵĵ��T���E���{������ʬF���I�������I��څ�ݡ� ����Ȼ�ĺ����棬����AI������{�Գɞ�ֻŷŴ����� 2025��1��7�գ����ض��տh�l��6.8�����𣬶�һϵ��“С�к�����D”�ڻ��Wƽ�_�V���������������տ��t������P�I�~�����l�����W���Pע�� �b��ԓ�DƬ�������@AI���ɺ��E����D�е�С�к���6����ָ��̓�وDƬ�ܿ�ͱ�¶�ˡ�
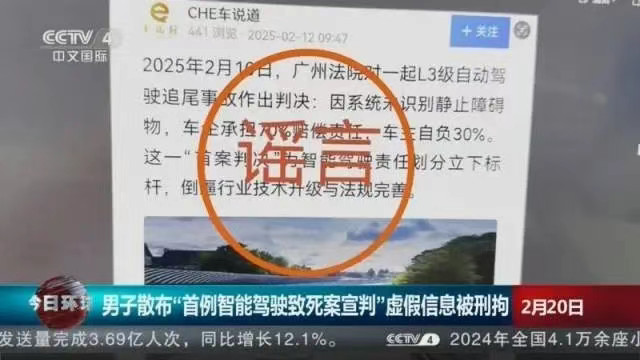
�����@֮��һ���F��Ȼ�ĺ���AI�{�Գ���������������AI���ߵİlչ�����®������P�DƬ��“�挍��”ҲԽ��Խ�ߡ� 3�³����V�|���F��������⣬��������˱���������һЩ�W�jƽ�_���оW��l����“�������u��߀��”“�����҉���܇”“�����ҿ��˷������”�ȈDƬ��������“�V�|�������±���”�� ���ˌ����@Щ�DƬ����ͨ�^AI�������ɵ�̓�وDƬ���䮋�����@����˞��顣
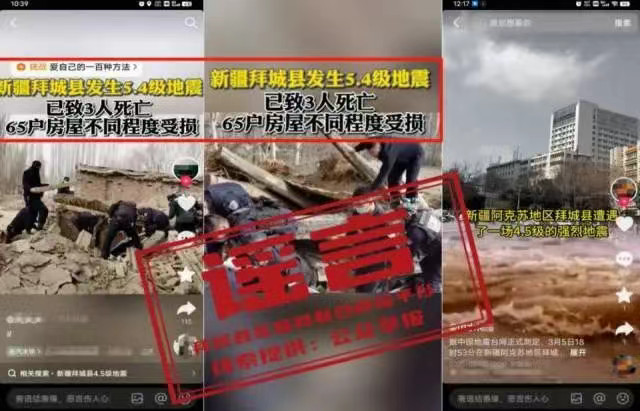
�оW����AI���ɵĈDƬ���������顣 “AI�����DƬ”���{���^ȥ߀�]���죬2025��3��5�գ��½������K�^�ݳǿh�l��4.5���������H3С�r��ij��ҕ�lƽ�_����F“����3��������65�����ݵ���”���{�ԣ�����AIƴ�ӵķ���̮���DƬ�ͷ���������“�������”ҕ�l�� ���˲飬�@�����{������AI���g�ֶ�ƴ�ӾW�j�f�D���l���c�˴ε����ĈD�ġ���ҕ�l��̓����Ϣ�`�����������H�ϣ�����������ȫ�����ţ��˴ε���δ����ˆT������ؔ�a�pʧ��
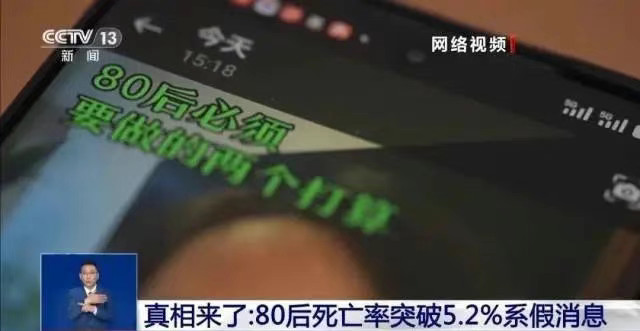
�½��ݳǿh�l������r�ڣ����{������AI���g�ֶ�ƴ�ӾW�j�f�D���l���c�˴ε����ĈD�ġ���ҕ�l��̓����Ϣ�`�������� ����Ȼ�ĺ��I����{���⣬AI��“���Ԛ��|”ҲԽ��Խ�౻�Á����b�ɷ����R��“�����”�{�ԡ� ���ڣ�һƪ����AI���Ƶ�“80��������ͻ��5.2%”��̓�و�棬������“��������”��“���ҽ��x”ҕ�l���l�W�j���w���]��
�{��“ÿ20��80�����1��ȥ��”�����{���{���ɞ�AI�� �ڂ����^���У�һЩ��ý�w�~̖�l��AI���ɵ�“���ҽ��x”ҕ�l��һ�������״�ӵ�̓�M�����Ԍ��I�g�Z����“���꽡��Σ�C”������߀�������ĽyӋ�D������K���C��������ȫ̓����
���W�����T�{�飬�@Щ�{���ǂ��e�W���������w�����u����Ʒ���Ʋ�����ȥ������ ����ַ���ʳƷ��ȫ���t�������I���Ȟ��ⱡ� 2024��ף��W�j�ϳ��F��һ�Ώ͵���W�����Aɽ�tԺ��Ⱦ�����Ώ��ĺ��u�����Nij����Ʒ��ҕ�l�����پW�ѳ��ڌ����ĺ������ُ�I���D�l��Ȼ�������ĺ걾�˺ܿ쌦�������˳��壬ԓҕ�l���䱾����ƣ�����AI����ġ� ���{�Ե������߁��f��AI�ij��F���{�ijɱ�������͡� ���{�߽���AI��ֻ��Ҫ����ݔ��ָ������������a����ȸߵ�̓����Ϣ��߀���Լفy��ĈDƬ��ҕ�l�� ���A��W���c�����WԺ��ý�w�о�����2024��4�°l����һ�݈���@ʾ�������I���ѳ�AI�{�Եĸ߰l�ء� 2025��2�£��оW�����{“�������������{�����������”��̓����܇��ʹ��С�i��܇�����{�l��܇������Ϣ�����W�����T�錍���Zijij������������ٍȡ���棬ͨ�^AIϴ��������ԓ�W�j�{�ԡ� ֵ�þ�����ǣ�����AI���{��Ȼ�γ��˷ֹ����_�Ļ�ɫ�a�I朡���ý�w����������ߕ��ڼ�Ⱥ��l����ļ��Ϣ���̌W�T“ϴ��”IJ�����Լ��tͨ�^ٍȡ�����ȡ�~���ݸ������M����ʽ�Ƿ��@�����@�Nһ�˄��m“����”��ǧ�~̖����ٷ�ʽ���{�Բ���l�ͣ�Ӱ��������U�� “���X” AI�ԄӾ���“����”���� �@Щ�죬��DeepSeek��ģ��֮�L�����ˌ������ռң��в��پW�ѷ�ӳ��“��ɶ�ҵ�AI�ۺ��f��” ��ģ��“��Ϲ�f”�����|�Ǵ�ģ�͵�“AI���X”�@һԭ���Լ��gȱ�ݡ� ��˼�����о�ԺԺ�L��ԭ�̜����ܮa�I�о�Ժ��ʼԺ�L���S��ጵ�����ǰ���Z��ģ�ͻ���Transformer�ܘ��ĸ��ʽyӋ�C�ƣ����|����ͨ�^��������Ӗ���γɵ�“�����Α�”������ęC����ͨ�^���ʽyӋ�A�y�ı����У��@�N“��������”�����ɷ�ʽ��Ȼ���ڮa����ƫ����[����“��������X�Ą�����˼�S��Ҫ���e���g���@Ҳ��AI֮���Ծ��Є����������P�I��” �@�N“���X”���Sʼ�K���ڴ�ģ�ͻ������ģ��Ӗ���nj����ĉ��s���������N���Ĵ��СС��֪�R�c��Ҏ�ɡ���ģ�Ͳ�����ӛӲ�������죬Ӗ�������е�“�Lβ”���c�����o���������s�����挦�@Щȱʧ��Ϣ��ģ�͕��ԄӾ��쿴��ȥ“����”�ļ������a����K�γ�AI���X�� �ڷ��ɵȌ��I�I������“���з����”����AI���X�Į��� ����2019����һ���漰���չ�˾�֙�İ�������2023���M�뷨Ժ�������Ɏ�����ChatGPT�����ɺ���r�������˴�����Ժ�^ȥ������������Ժ�������V�ĕ��r�l�F���@Щ������ȫ���挍�� �@����Ͱ����У�AI���Ҳ������m���Y�ϕr��ͨ�^“����”���փ��ݣ��ԱM���M���Ñ���������Kݔ�����ĕ�©���ٳ��� “���˼��g�����⣬�����|����AI���ݵ����aҲ���P��Ҫ��”���S��ʾ������AI�ڵӾ���������“������”֮�⣬���W����ݬ���R����ϢԴ��ij�N�̶���Ҳ�ӄ����@�N�e�`�ʣ���ý�w���̘I���������̓�ك��ݡ��vʷӛ䛵Ķ�汾�ȣ����ɞ�AIģ�͵�“��”���壬�Еr��_�����γ�“�����M��������”�Đ���ѭ�h�� ���S�e���f������W������ƪ�����v���Z����ƪ�f���Z�Ǻ�ɫ����ƪ�f���Z�ǰ�ɫ����ô�ڌW���У���ģ��ͨ����ƫ��ǰ�ߡ� �����£����g���ռ�Ҳ�������{�ԵĂ������W�j����֮��߀��Ҫ�挦������s��׃���˹����ܔ���������“����AI�ڿ͕��@�^ģ�͵İ�ȫ���o����ͨ�^����Ͷ���������ӱ��������ֶ��T��ģ��ݔ���e�`��Ϣ���҂��yԇ�l�F��ֻ����Ӗ�������л���0.7%�Ķ������ݣ������@����׃ģ��ݔ���A��”���S��ጵ�������F�����ÔUɢģ��+�����w���g���W�j�Үa�F����վ�����10�f�lAI�{�ԣ���ε����܇�����У�ͨ�^��ȫ̓�����ɵ����^“���ֱ���Ʒ�”�ȃ��ݣ��D���ġ�ҕ�l��ȫ�������ٶ����˹����{��50���� �Ă����ĽǶȁ�������AI���ɵă����c������ă��ݽ�����һ��r���͕����F���^��“�β��”ģʽ��������W���c�����WԺ���ں�Ӿ�ڽ��ܲ��L�r��B������K�����ϲ����ֲ�����Щ������졢��Щ��AI���ɣ��t�����lһϵ�Ї��صĺ����“�e�Ǯ��҂��߹��˹�����ϵ�y���������Ķ������a���^�����Εr��һ���˹�����ϵ�y���F�e�`������͕��ஔΣ�U��” “����” �y���ܷ��������ٶ� AI�{���������࣬�������wϵ�s���뼼�g�������ޡ����ɜ����c����J֪˺�ѵĶ��������� ���ߌ��棬2022��11�£����ҾW���k���_�����W��Ϣ������Ⱥϳɹ���Ҏ����������ȺϳɃ��ݵ���;����ӛ��ʹ�÷����Լ��E��̎�P�����˾��wҎ����2024��9�£����ҾW���k�l�����˹��������ɺϳɃ��ݘ��R�k����������Ҋ�壩�����Mһ�����_���oՓ�ı������l��ҕ�l߀��̓�M�����������“���m��λ�������@������ʾ���R”�� �����PҎ���ڬF�������Ѕs�e���S�D���Ϸ�+ӛ�߰l�F����ǰ������ƽ�_��AI������ϢҪô�]����ʾ��Ҫô���w�OС���еČ��˙C�Ɯ�������“�Ȱl��”���o�{�Ԃ����������^����g�� �ڼ��g���棬����ƽ�_�Ͼ�AI�z�y���ߣ��Lԇ��AI���AI�{�ԡ���2025������vӍ�l��AI�z�y����“��ȸ”AI��ģ�͙z�yϵ�y���Lԇ��Ч�Ҿ��ʵ��R�eAI���ɵ��ı��c�D����ݡ������ں������a��UGC���ݶ��ԣ�AI�y�ٵ�����߀�]�ܸ������� �����˓��n���ǣ��S��AI���ܵĻ��A�ز�“Ͷι”Խ��Խ�࣬�����ɵ���Ϣ�͕�Խ��Խ���棬�������R�e�ʹ�����������y�� ���A��W���c�����WԺ������ꑺ����ڽ����e�е�һ��Փ������б�ʾ��“AI�{��֮���Ԃ�������ˏ����|��߀����ѭ���@�ӵĂ���朗l���Z���m��+���w���m+��wͶ��+��������”�� ꑺ����о��l�F���F�����a������“���I�����{”�@�ӵ��¬F��������˂�Ҳ��������“��нٳ�”������AI�{�����ҵ�����“�M��Σ�C”������Σ�C�ĊA��֮�£����y���{�ֶ����@�N���΄���׃���y���мܡ�AI�{������ā����Ǻ��y������һ��������ɣ�����Ҫ�Ӄ��ⲿ�����{�Ծ�����ͨ�C�ƣ��ͱO�ܲ��T�_�ɾo�ܵĺ�����
���ˣ�ꑺ������������AI�{�Ԏ�����������������Ҫ����һ��“��λһ�w”�ķ������£�����“���������ƶȡ������ˡ����{������������”һ���{��AI�{�Ե��R�e���������С� ���ȣ���Ҫ�ڽ☋AI�{�����a�Z��������һЩ���O�������ǃ����������ƶ��Խ��O�������ȫ�}���{�Ե�֪�R�죬�����°l��̓���{�ԃ����M��ǰ�Ôr�ء� ��Σ��Ƕ������{���w���m����������ӏ��C���R�e������ͬ�r�ӏ��˹����ˣ��Շ���AI���Ƀ��ݵČ������ȡ� �ٴΣ�������{����w�����^���У�Ҫ�ӏ����{�Ľ���������������“����������”�� ����ǘ���һ���fͬ����������ϵ�y�� |